Evaluación de la pérdida de calidad del audio usando el codec Opus en tareas de auscultación remota¶
Juan M. Fonseca-Solís · Agosto 2020 · 10 min read
Resumen¶
Con el auge actual de la tele-medicina, la industria médica se ha dedicado al desarrollo de estetoscopios digitales con el fin suplir la demanda de hospitales y clínicas que buscan auscultar a sus pacientes remotamente. El desarrollo de estos aparatos no involucra solamente la construcción del hardware y del software, sino también en desarrollar la infraestructura necesaria para transferir los datos hacia los médicos o los servidores que corren los algoritmos de reconocimiento de patrones. De acuerdo a la literatura científica, parte de esta infraestructura involucra el uso del códec Opus, que también es empleado por plataformas de videollamada como Zoom, MS Teams y Skype. Opus, a pesar de ser uno de los mejores métodos de compresión de audio, es un algoritmo "con pérdida", lo que significa que altera el contenido frecuencial para que sea audible solo por el oído humano. Esta modificación deja en desventaja a los algoritmos de reconocimiento de patrones que podrían requerir analizar todo el espectro de la señal. En este ipython notebook analizamos la alteración que produce Opus a sonidos del corazón y los pulmones para determinar si la pérdida de la calidad aún con una tasa de bits de 128 kbps puede afectar a un algoritmos de reconocimiento de patrones. Los resultados obtenidos son preliminares, pero muestran que aplicando un filtrado pasa-bajas la distorsión es aceptable.
 Figura 1. Tomada de https://pixnio.com/es/ciencia/ciencia-medica/estetoscopio-telefono-movil-diagnostico-pulso-cardiologia-medicina-atencion-medica.
Figura 1. Tomada de https://pixnio.com/es/ciencia/ciencia-medica/estetoscopio-telefono-movil-diagnostico-pulso-cardiologia-medicina-atencion-medica.
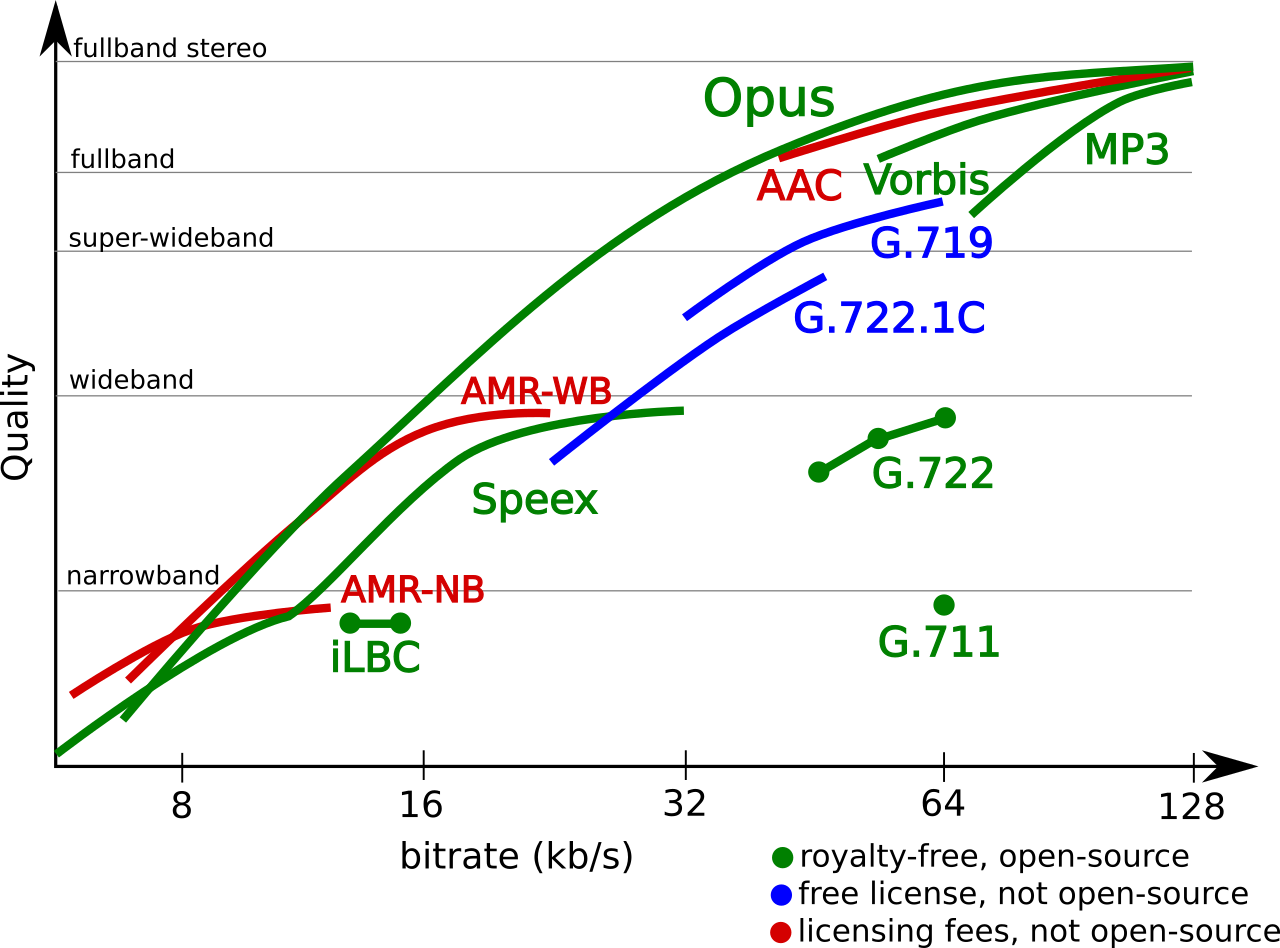 Figura 2. Rendimiento del algoritmo Opus (tomada del sitio de Opus
Figura 2. Rendimiento del algoritmo Opus (tomada del sitio de Opus 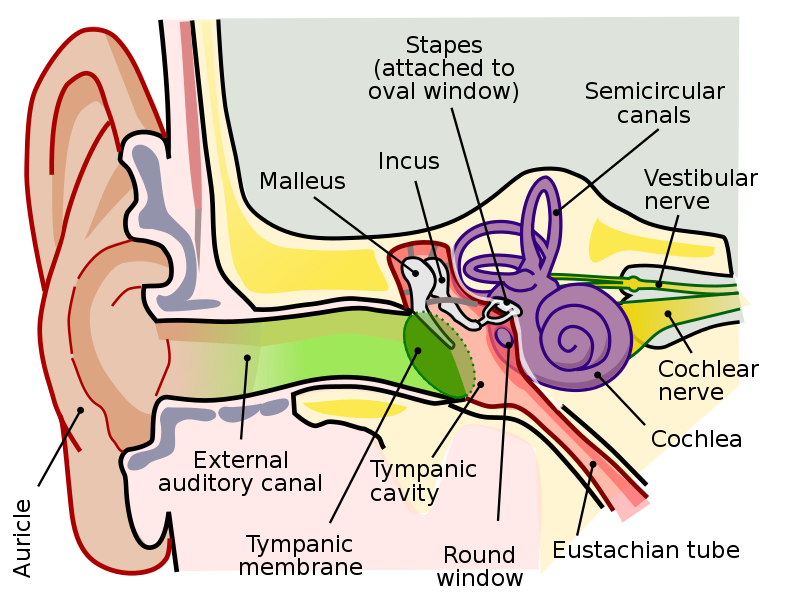 Figura 3. Tomada de
Figura 3. Tomada de 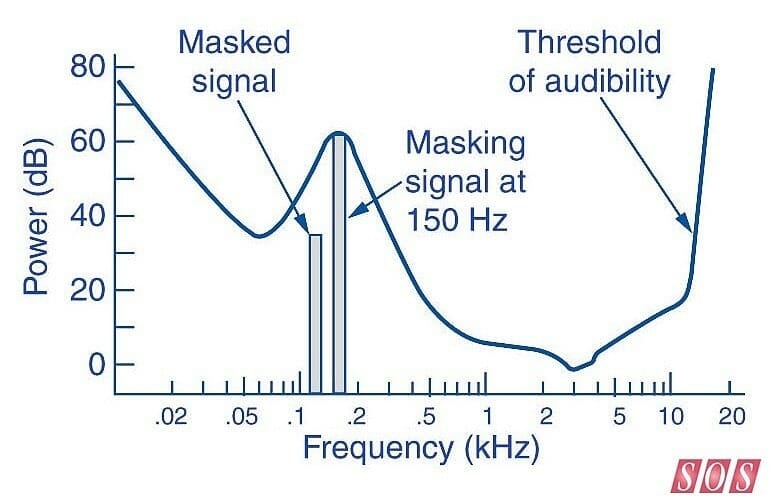 Figura 4. Ilustración del audio interno, medio y externo (tomada de
Figura 4. Ilustración del audio interno, medio y externo (tomada de 

 Figura 5. Posiblemente, como se vería nuestro médico auscultando remotamente y sin video a nuestro paciente. Tomada de
Figura 5. Posiblemente, como se vería nuestro médico auscultando remotamente y sin video a nuestro paciente. Tomada de 


















{kind=link}
{kind=link}